Links Úteis
Guia de Métricas
| Nome da Métrica | Pra que serve? |
|---|---|
| Acurácia | Mede acertos sobre todos os casos. |
| Precisão | Mede a porcentagem de acertos do que eu quero (exemplo, achar SPAMs) sobre todas as tentativas. |
| Recall | Porcentagem de acertos do que eu quero (SPAMs que acertei) sobre todos os casos que eu quero disponíveis (todos os casos de SPAM). |
| F1 Score | Média harmônica entre precision e recall. Útil para dados desbalanceados. |
| Área abaixo da Curva ROC (AUC-ROC) | Gráfico com o desempenho do modelo usando diferentes thresholds (pontos de corte). No eixo X são os falsos positivos (onde o modelo disse que era SPAM, mas não era). No eixo Y são os falsos negativos (onde o modelo disse que era NÃO SPAM, mas era). Quanto mais perto de 1, mais perfeito o modelo é (menos erra). |
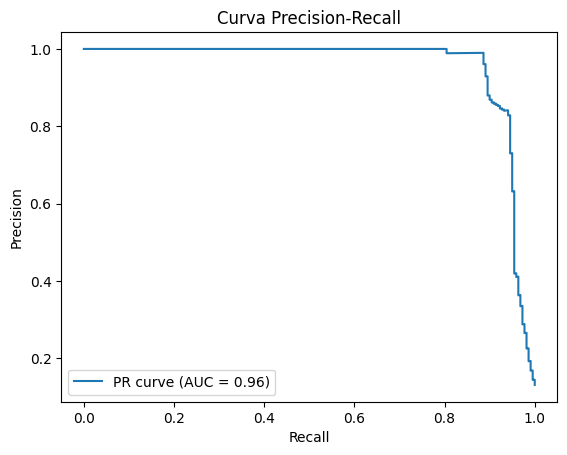
| Área abaixo da Curva Precision Recall (AUC-PR) | Gráfico com o desempenho do modelo usando diferentes thresholds (pontos de corte). No eixo X são os valores de recall. No eixo Y são os valores de precisão. Quanto mais perto de 1, mais perfeito o modelo é (menos erra). |
Exemplo de AUC-ROC

Exemplo de AUC-PR
O que será feito na avaliação?
- Criação de um modelo de classificação binária, usando aprendizagem supervisionada — ou seja, dividindo a base de dados em treino e teste — e avaliando o desempenho desses modelos. A base de dados será em TEXTO;
Passo-a-passo da avaliação
Balanceamento dos Dados
- Para verificar o balanceamento, basta calcular a porcentagem de cada classificação sobre o total.
- Por exemplo, numa base onde existem textos classificados como SPAM e NÃO-SPAM, calcular a porcentagem de cada um na base de dados.
- No Pandas, os valores podem ser vistos com a função
value_counts.
df['target'].value_counts() # 'target' é a coluna com a classificação
# A porcentagem pode ser calculada da seguinte forma
porcentagem_negativos = df['target'].value_counts()[0] / df['target'].count() * 100
porcentagem_positivos = df['target'].value_counts()[1] / df['target'].count() * 100
print(f'Porcentagem de casos negativos (0): {porcentagem_negativos:.2f}%')
print(f'Porcentagem de casos positivos (1): {porcentagem_positivos:.2f}%')Extração de Características
- Computadores não entendem o que textos significam.
- Por isso, extraímos as características que queremos do texto (transformando em números).
- Existem duas abordagens principais para a extração de características
Top-Down
- Provavelmente não será cobrada.
- Entende o sentido das palavras.
- Exemplos: LDA (Latent Dirichlet Allocation), Word2Vec, etc.
- No LDA, buscamos as palavras mais importantes do texto.
- Exemplo: Google Colab
# Importar bibliotecas necessárias
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
import numpy as np
# Exemplo de documentos
documents = [
"Machine learning is amazing! It's the future of technology.",
"Natural language processing is hard and can be frustrating at times.",
"Deep learning techniques are great for solving complex problems.",
"Artificial intelligence will take over many industries soon.",
"Natural language processing is difficult but extremely rewarding."
]
# 1. Vetorização do texto (Bag of Words)
vectorizer = CountVectorizer(stop_words='english')
X = vectorizer.fit_transform(documents)
# 2. Aplicação do LDA (Latent Dirichlet Allocation)
lda = LatentDirichletAllocation(n_components=2, random_state=0)
lda.fit(X)
# 3. Mostrar os tópicos e as palavras mais importantes em cada tópico
def display_topics(model, feature_names, no_top_words):
for topic_idx, topic in enumerate(model.components_):
print(f"\nTópico {topic_idx + 1}:")
print(" ".join([feature_names[i] for i in topic.argsort()[:-no_top_words - 1:-1]]))
# Número de palavras para mostrar em cada tópico
no_top_words = 5
display_topics(lda, vectorizer.get_feature_names_out(), no_top_words)Saída de Exemplo:
>>> Tópico 1:
>>> learning techniques complex problems great
>>> Tópico 2:
>>> language natural processing difficult extremelyBottom-Up
Vetorização Por Sentimentos
- Provavelmente não será cobrada.
- Busca pontuar palavras como negativas ou positivas.
- Usando um dicionário léxico pré-existente.
from nltk.sentiment.vader import SentimentIntensityAnalyzer
import nltk
# Baixar os recursos do VADER
nltk.download('vader_lexicon')
# Inicializar o analisador de sentimentos VADER
analyzer = SentimentIntensityAnalyzer()
# Exemplo de documentos de texto
documents = [
"Machine learning is amazing! It's the future of technology.",
"Natural language processing is hard and can be frustrating at times.",
"Deep learning techniques are great for solving complex problems.",
"Artificial intelligence will take over many industries soon.",
"Natural language processing is difficult but extremely rewarding."
]
# Analisar o sentimento de cada documento
for doc in documents:
sentiment = analyzer.polarity_scores(doc)
print(f"Documento: {doc}\nSentimento: {sentiment}\n")Saída de exemplo:
>>> Documento: Machine learning is amazing! It's the future of technology.
>>> Sentimento: {'neg': 0.0, 'neu': 0.662, 'pos': 0.338, 'compound': 0.6239}
Os valores retornados são:
- neg: negativo
- neu: neutro
- pos: positivo
- compound: score geralTF-IDF
- Conta as palavras dentro do corpus.
- Quanto mais frequente uma palavra, mais importante ela é.
# Importando a classe do TF-IDF
from sklearn.feature_extraction.text import TfidfVectorizer
X_train_indexes = X_train.index
X_test_indexes = X_test.index
X_train_text = df['text'].iloc[X_train_indexes]
X_test_text = df['text'].iloc[X_test_indexes]
# Vetorizando a parte de texto e teste
vectorizer = TfidfVectorizer()
X_train_tfidf = vectorizer.fit_transform(X_train_text)
X_test_tfidf = vectorizer.transform(X_test_text)Modelos de Classificação Binária
Random Forest Classifier
- Scikit-learn: RandomForestClassifier
- Constrói várias árvores binárias, e faz uma “votação” entre os resultados, pique segundo turno das eleições presidenciais.
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
# Treina o modelo
model.fit(X_train_tfidf, y_train)
# Retorna as previsões, classificadas em 0 e 1
y_pred = model.predict(X_test_tfidf)
# Retorna as previsões em probabilidade (0.00 até 1.00)
y_pred_proba = model.predict_proba(X_test_tfidf)Hyper-parâmetros
n_estimators: número de árvores na floresta.- Aumentando o valor, o modelo é mais performático, mas demora mais para processar uma determinada instância;
bootstrap: cada árvore é treinada com um conjunto aleatório de dados;
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=500, bootstrap=True)
model.fit(X_train_tfidf, y_train)Naive Bayes Multinomial
- Scikit-learn: MultinomialNB
- Usa o Teorema de Bayes para determinar se um evento pode ocorrer ou não, considerando um segundo evento.
- Muito usado para classificação de texto.
- Usa a contagem de palavras para determinar a classe.
Hyper-parâmetros
alpha: garante que o modelo não fica confuso com novas palavras.fit_prior: usar o balanceamento em conta?- se
True, o modelo irá considerar o balanceamento para dizer a probabilidade de cada instância. - exemplo: se a maioria é SPAM, ele usará dessa informação para decidir.
- se
False, o modelo considera chances iguais (50%/50%) para ambas classes. - útil para que o modelo não fique tendencioso.
- se